论文阅读_图像生成-ProgressiveGAN:Progressive growing of GANs for improved quality, stability, and variation
Progressive GAN,所生成的图像分辨率达到了$1024*1024$,先睹为快:

不得不说,确实很真实~~
那么我们就要问了,市面上这么多GAN,凭什么你ProgressiveGAN生成的分辨率就这么又高又真实呢?
君且安坐,请看下文如何分解。
1. methods
其实ProgressiveGAN,关键在于这个 Progressive, 看图:
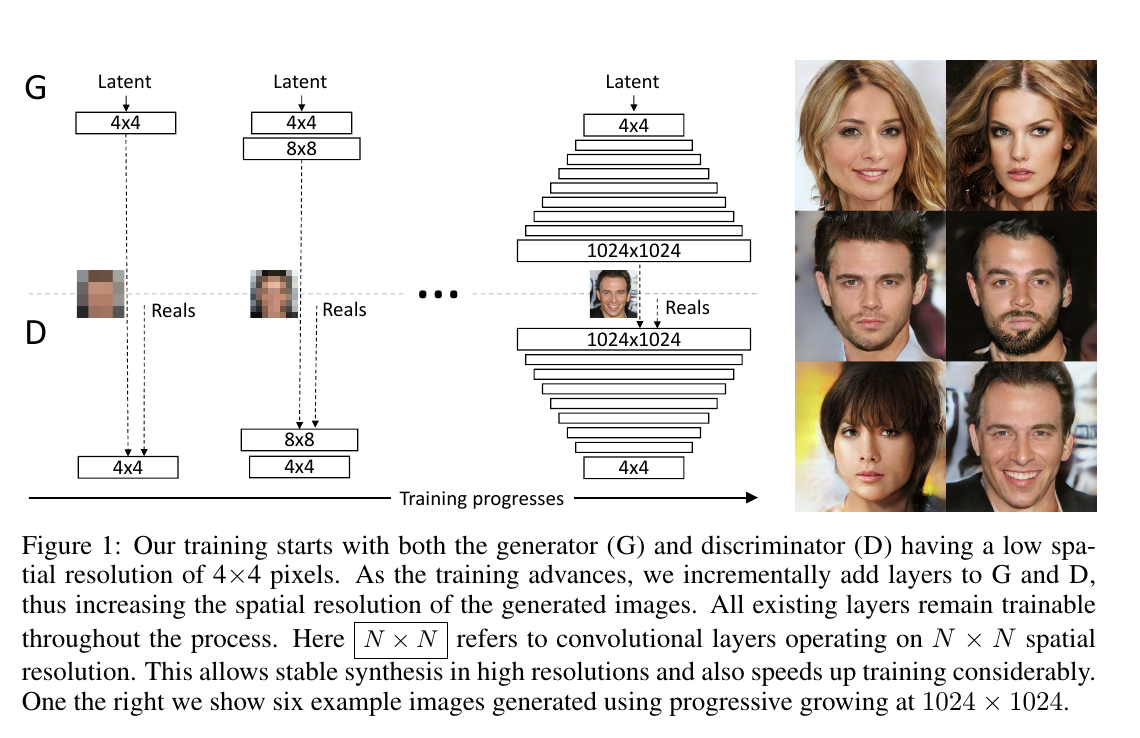
所谓 Progressive,就是先从低分辨率的图像开始训练,然后 渐进地 增加generator和discriminator的层数,以此来达到增加生成图像分辨率的目的。
同时,可想而知,每次新添加层数的时候,因为相当于pretrain了前面的层数,所以训练过程也会更快更稳定一点。
但即便如此,作者还不满足,其在添加新的层的时候,还要做点小动作:
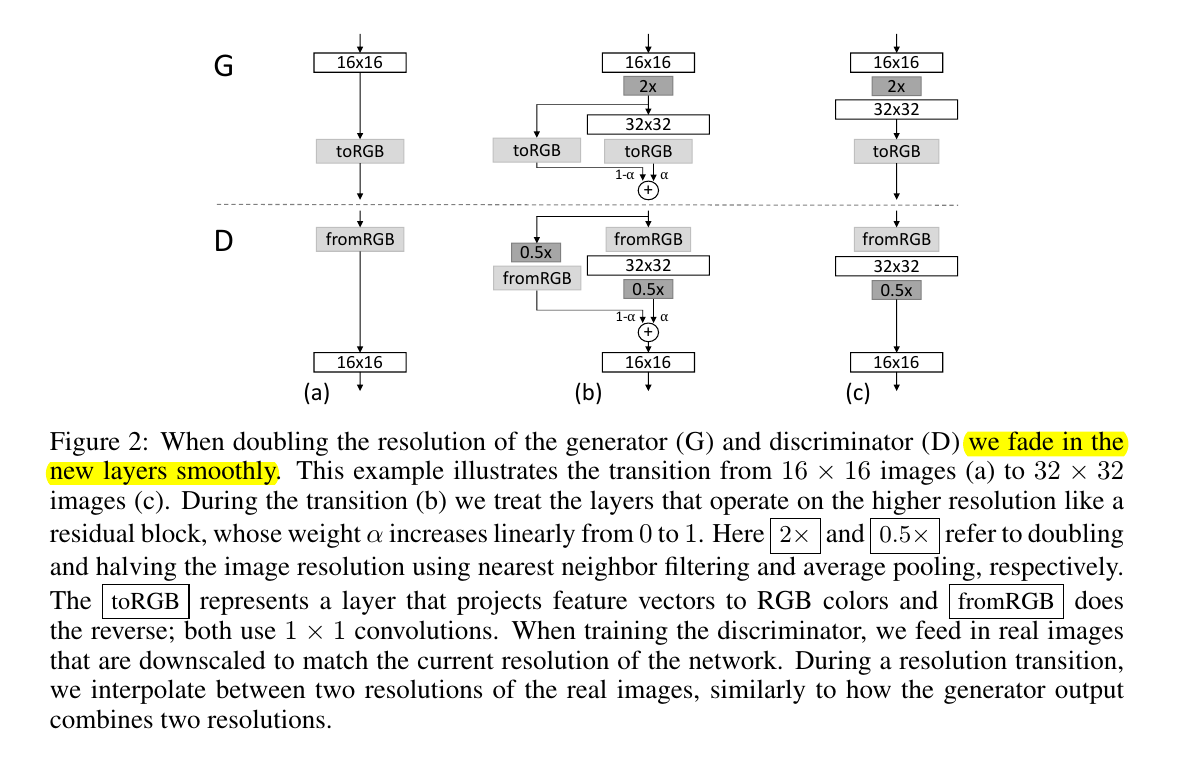
看懂了么,解释有点绕,其实就是在添加新的层的时候,将其作为一个residual layer,从0到1递增地增加其权重,以达到稳定训练的目的。
2. tricks
下面就是论文中用到的一些tricks来达到更好的效果了~~
1). increase variation using minibatch standard deviation
众所周知,GAN容易陷入 mode collapse, 即只学习到了几个样式,比如本文的人脸任务,很可能最终学到的只是为数不多的几个人脸。
这可如何是好呢?
这篇论文用到的方法是改进的 minibatch discrimination。
什么意思呢?就是每次用一批图像,计算其特征统计(feature statistics),从而使得generator生成的图像和训练用的图像有相似的统计(statistics)。
具体到这篇论文中的方法是:
- 计算这个minibatch每个特征(feature)在每个空间位置(spatial location)上的标准差;
- 将标准差在所有features和spatial locations上求平均,得到一个数值;
- 复制这个数,并将其concatenate到该minibatch的所有spatial locations上,从而得到一个额外的feature map。
- 这个feature map可以插入到discriminator的任何层,但作者发现插入到结尾部分效果比较好。
于是,最终得到的generator和discriminator的网络结构如图:
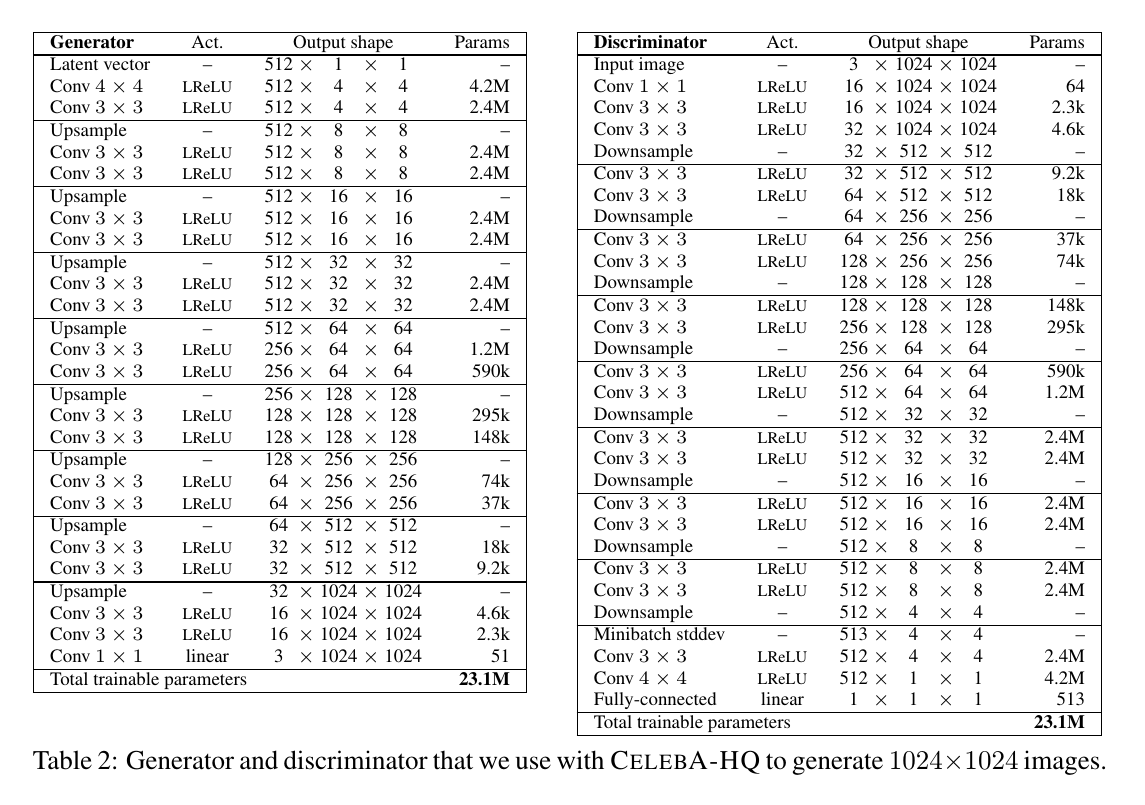
可以看到,generator和discriminator的结构几乎是镜像对称的,在discriminator的最后两个卷积层之前有个 minibatch stddev层,
其维度为\(513*4*4\),比上一层多了一个维度,所多的即为前面提到的新生成的feature map。
2). normalization in generator and discriminator
GAN本身很容易因为generator和discriminator的不健康竞争而使得signal magnitudes增大,特别是当没有使用类似batch norm之类的约束的时候。
而batch norm这类方法最初是被用来消除covariate shift的,但是,作者说并没有在GAN中观测到covariate shift的问题,也因此采用了不同的方法。
请看下文分解。
a. equalized learning rate
不用于当前流行的精细设计的权重初始化套路,作者使用了一个普通的\(N(0,1)\)初始化,选择在训练时进行显示地权重归一化。
该方法的好处与当下流行的一些梯度下降算法(RMSProp, Adam, etc)相关。这些算法通过其所估计的标准差来归一化梯度的更新,也因此是独立于参数的大小的。
如果某些参数相比于其他参数有更大的波动范围的话,其也会花费更长的时间来调整。相应的,其学习率(learning rate)就并不能适用于所有参数。
这时就体现出作者的意图了:在训练时保证参数的波动范围,于是乎,就能保证同一个学习率对于所有参数是适用的。
b. pixelwise feature vector normalization in generator
为了防止generator和discriminator的参数量级因相互竞争而变得过大,作者又在pixel层面上使feature vector归一化到单位长度:
\(b_{x,y}=\frac{a_{x,y}}
{
\sqrt
{
{
\frac{1}{N}
\sum_{j=0}^{N-1}
{(a_(x,y)^j)^2}
+\epsilon
}
}
}\)
式中,$\epsilon=10^{-8}$,$N$是feature map的数量,$a_{x,y}$和$b_{x,y}$分别是像素$(x,y)$的原始feature vector和归一化后的 feature vector。
3. trivials
剩下的就是实验对比环节了,没啥好说,无非是在什么什么数据集上,用了什么什么标准,超过了start-of-the-art多少多少~~
不过其中有一个操作倒还值得一提:如何生成的CelebA-HQ数据集。
文章作者自己从CelebA中生成了30000张1024x1024分辨率的高清大头照,其主要流程如下图:

具体操作步骤为:
- 利用预训练好的卷积自编码器来去除自然图像中的JEPG artifacts;
- 利用对抗训练生成的4x super-resolution网络来提升4x分辨率;
- 采用padding和filtering来扩展脸部区域超出的图像的维度;
- 根据CelebA数据集中的脸部landmark annotations来选择裁剪的矩形框:

最终在202599张图像中得到了30000张高清大头照。
4. results
最后,就是大家喜闻乐见的有图有真相环节了~
话不多说,放图:



好了,就放这么多啦,还没看够的话,可以前往youtube观看其演示视频,
或者你也可以查看其论文的appendix:ProgressiveGAN。
5. ends
以上,就是这篇ProgressiveGAN的阅读所得。
欢迎大家指摘讨论~~
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.