论文阅读-可迁移对抗样本攻击
Hello 大家好,本次带来的是针对目标检测的可迁移对抗样本攻击。
听起来好高大上的样子,其实就是对抗样本攻击,不过这次用在了目标检测上,然后加了个小trick, 使得攻击方法可以在两种目标检测方法上都奏效,所以就说是可迁移的。
具体如何呢?我们一一道来~~
1. 前情提要
众所周知,当前的目标检测模型有两类:proposal based models and regression based mod-els。其实就是一个是基于锚框,一个是直接回归。
然后作者分析了一波目前已存的针对目标检测的对抗样本攻击方法,大部分都是针对proposal-based models的:

于是乎作者眼睛一转,计上心来:
不管你哪种方法,你总要有 feature map 的吧?那我把 feature map 也给攻击了,岂不就是一个大一统的攻击方法了?
好的,上面这句话就是全文的 文眼 了,下面我们看作者究竟使些什么手段。
2. UEA(Unified and Efficient Adversary)
怎么样,光看这个 UEA 的名字是不是也觉得很像大一统的意思?野心很大啊~~
模型框架结构如下:
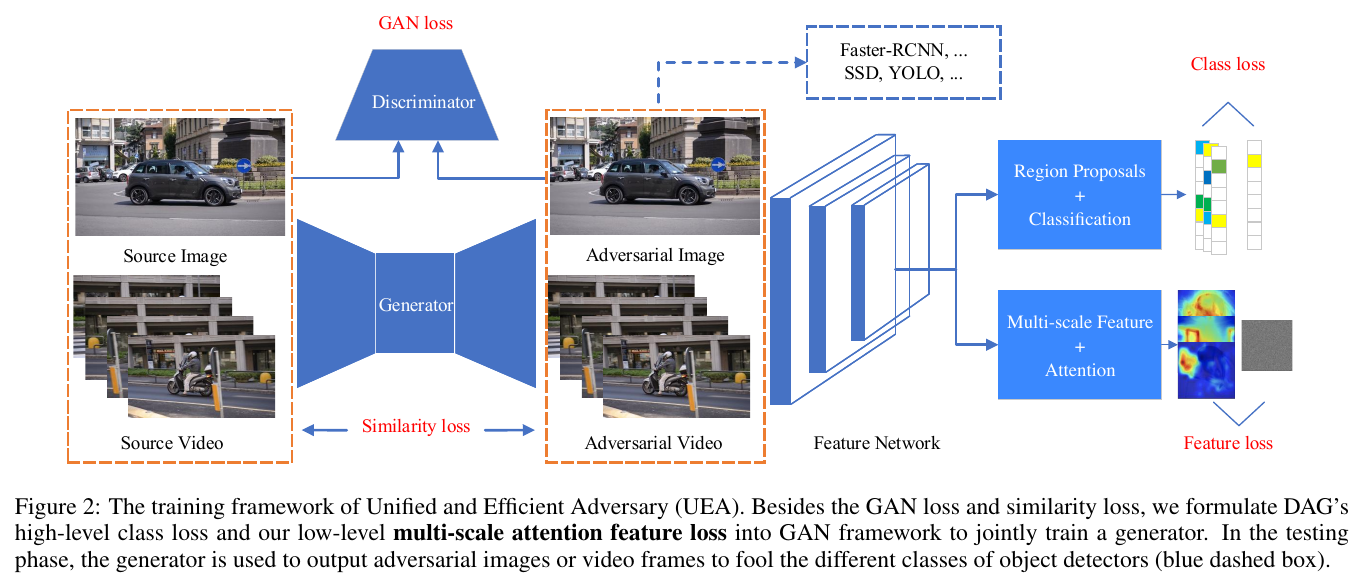
具体来说,就是用 条件GAN(conditional GAN)来生成对抗样本,不过在其上多加了几个损失函数来监督生成器的生成效果。
第一个当然就是 $L_{cGAN}$:
然后加了个$L_2$ loss:
\[L_{L_2}(G) = E_I[||I-G(I)||_2]\]当然,只有这两个的话,就只是个单纯的复制网络了,肯定不行,还加了个 Adversarial examples for semantic segmentation and object detection
里用的 misclassify loss:
式中,$X$ 就是 feature map, $\tau = {t_1, t_2, …, t_N}$ 是 $X$ 上的 proposal regions,阈值为 0.7, $l_n$ 是 $t_n$ 的
ground-truth label, \(\hat{l}_n\) 是从其他错误 labels 里随机取样的错误 label,$f_{l_n}(X,t_n)\in\mathbb{R}^{C}$
则指 $t_n$ 的 classification score vector (before softmax normalization)。
说到这里,如果你还没被绕晕的话,就会发现这个 misclassify loss 仅仅是针对 proposal based models 的,那前面说的针对 feature map 的攻击怎么实现的呢?
这就是下面这个 multi-scale attention feature loss 了:
式中,$X_m$ 是 m 层的 feature map, $R_m$ 是随机定义的一个 feature map, $A_m$ 是所谓的 attention weight。
于是乎,这最后一个 multi-scale attention feature loss 就实现了作者所说的 Unified and Efficient Adversary 了。
于是乎,最终的损失函数为:
\[L= L_{cGAN} + \alpha L_{L_2} + \beta L_{DAG} + \epsilon L_{Fea}\]不消说,$\alpha, \beta, \epsilon$是权重系数,$\alpha =0.05$, $\beta =1$, \(\epsilon = \left \{ 1*10^{-4}, 2*10^{-4} \right \}\).
3. 大功告成
最后就是些对比图了,可想而知,作者用的生成模型,那么对抗样本的生成时间自然大大缩短;
同时又把 feature map 给改了,自然对两种检测模型都能奏效。
放两张图:
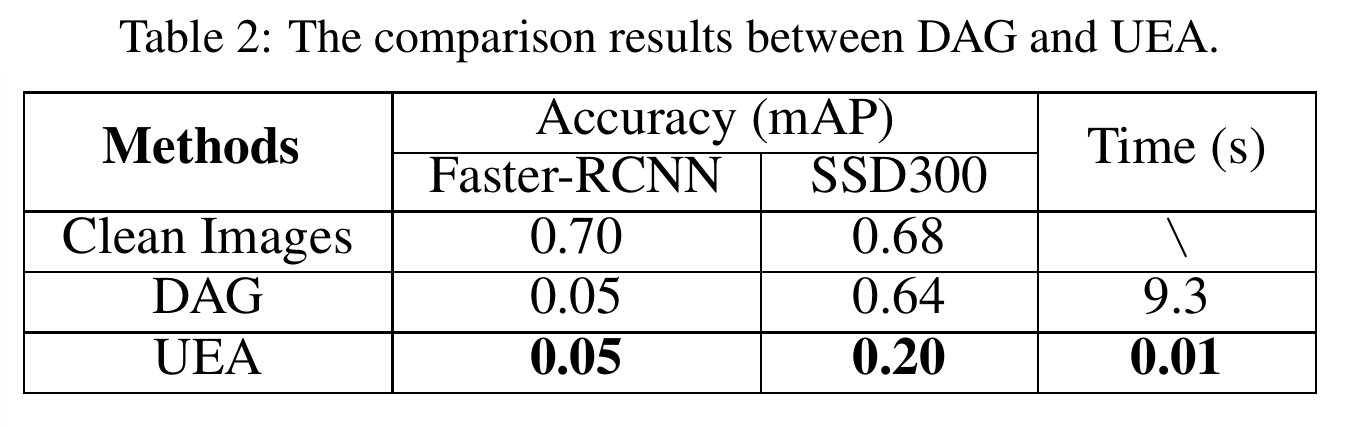

好啦,想看更多的图,敬请前往原 paper 观看~~
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.